GVPM: Garment simulation from video based on priori movements
Jiazhe Miao, Tao Peng, Ping Li, Li Li, Xinrong Hu, Bin Sheng, Tong-Yee Lee, Senior Member, IEEE

Abstract
Garment simulation plays an essential role in the virtual try-on and film industries. Computer graphics have extensively studied this field. Our proposed GVPM method is more cost-effective and easier to deploy than the physical simulation-based method for 3D garment animation. Previous methods generated videos with uneven transitions between the adjacent frames. Therefore, we propose to solve this problem using a priori motion-generation model that references similar poses to simulate expected motion. The motion sequences are then passed to the physics-based garment model we established, which recovers the pose from monocular video frames and extracts semantic information about the human body and garment to predict accurately how garments will deform according to the human pose. Thus, unlike some methods that use 2D images as input, GVPM is unaffected by body proportion and posture, resulting in diverse simulated garment results. Finally, combined with our temporal cue attention optimization module, the movements, joints, and forms are optimized to create dynamic garment deformations. As a result, our new approach can simulate 3D garment animations that display both virtual and real-world behaviors and extracts unknown body motions from other motion capture datasets.
Introduction video
Starting from the RGB frames of the input video. To extract semantic data about the body and clothing, we first preprocess the garment dataset to mimic different body forms and turn them into a normalized space. We use the predicted body geometry and texture avatars as the base body, obtain the action sequences and pass them to the garment module, add spatiotemporal cues to note the mechanism module optimization, and then mask them to produce the final result.
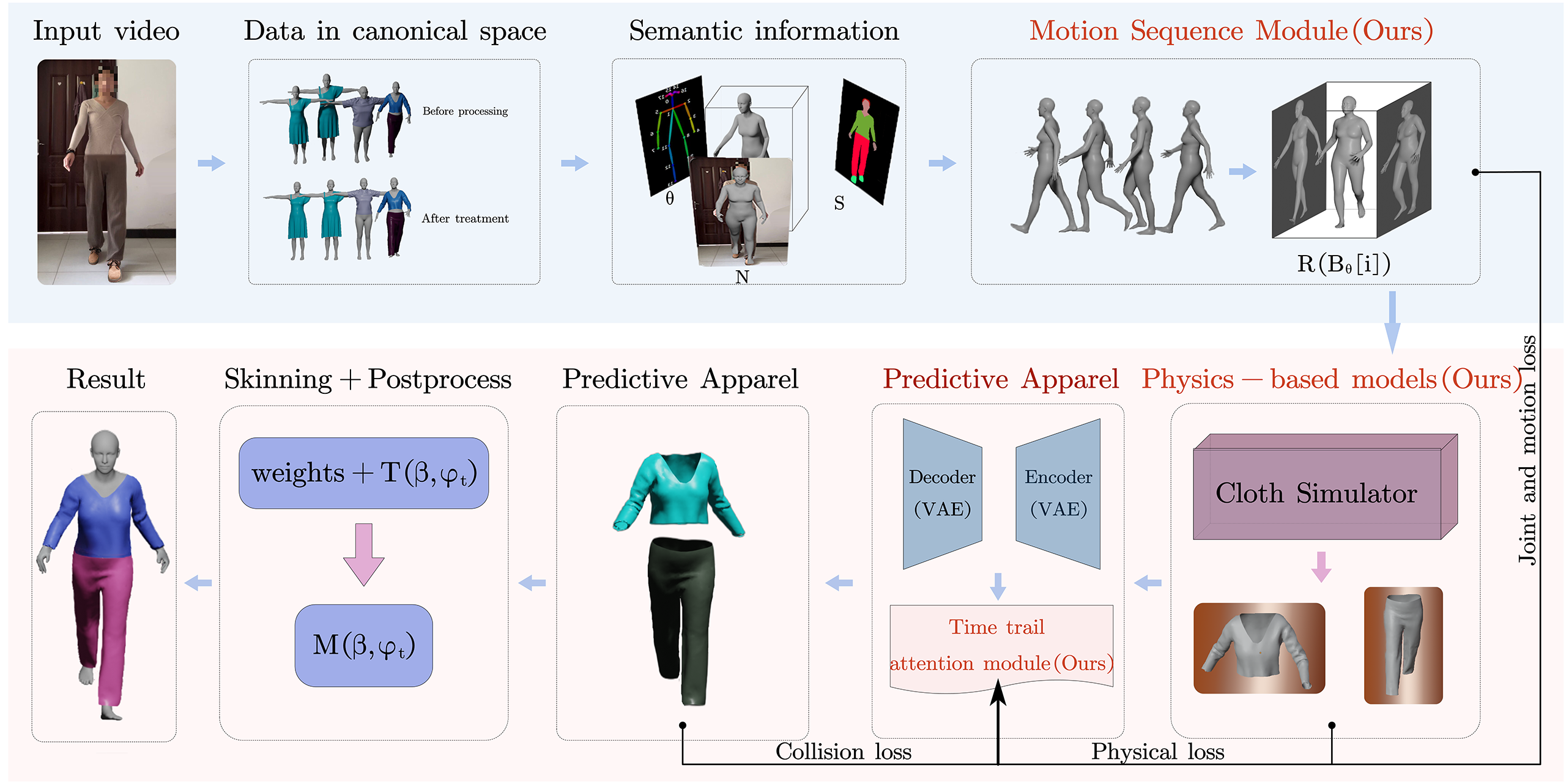
Related works comparison
Input is a video

The model learned from the video is applied to other datasets


Quantitative evaluation
| Methods | Tshirt | Top | Dress | Trousers | Tank top | Shorts | |
|---|---|---|---|---|---|---|---|
| PBNS SNUG GarSim Ours |
Euclidean error (mm) |
17.08 | 66.54 | 49.05 | 16.14 | 87.08 | 69.65 |
| 16.57 | 15.47 | 32.33 | 15.24 | 34.77 | 17.68 | ||
| 15.37 | 14.12 | 26.33 | 12.31 | 24.62 | 13.68 | ||
| 12.58 | 12.46 | 12.49 | 11.33 | 13.35 | 10.65 | ||
| PBNS SNUG GarSim Ours |
Edge | 0.69 | 0.46 | 0.89 | 0.56 | 1.24 | 0.33 |
| 0.71 | 0.37 | 0.76 | 0.46 | 0.65 | 0.42 | ||
| 0.63 | 0.52 | 1.14 | 0.62 | 0.58 | 0.21 | ||
| 0.66 | 0.43 | 0.75 | 0.53 | 0.44 | 0.26 | ||
| PBNS SNUG GarSim Ours |
Bend | 0.063 | 0.052 | 0.076 | 0.092 | 0.069 | 0.119 |
| 0.038 | 0.019 | 0.069 | 0.063 | 0.097 | 0.075 | ||
| 0.047 | 0.035 | 0.037 | 0.019 | 0.041 | 0.013 | ||
| 0.044 | 0.038 | 0.042 | 0.027 | 0.012 | 0.006 | ||
| PBNS SNUG GarSim Ours |
Strain | 0.144 | 0.231 | 0.043 | 0.331 | 0.117 | 0.041 |
| 0.066 | 0.183 | 0.058 | 0.065 | 0.102 | 0.026 | ||
| 0.053 | 0.296 | 0.022 | 0.256 | 0.136 | 0.038 | ||
| 0.078 | 0.083 | 0.031 | 0.081 | 0.069 | 0.029 | ||
| PBNS SNUG GarSim Ours |
Collision(%) | 0.95 | 1.13 | 1.33 | 1.34 | 1.27 | 1.47 |
| 0.36 | 0.78 | 1.68 | 0.45 | 1.62 | 1.67 | ||
| 0.69 | 0.49 | 1.12 | 0.66 | 1.56 | 0.88 | ||
| 0.41 | 0.53 | 1.19 | 0.61 | 0.69 | 0.51 |
Time, memory requirements and performance of state-of-the-art approaches are critical considerations in our work. Our method bypasses the costly expenses associated with data generation. While the cost increase compared to the baseline method is not particularly significant, we achieve a greater variety of clothing styles, more visually realistic results, and enhanced scalability when the input is in the form of a video.
| Methods | Train | Time | Memory |
|---|---|---|---|
| PBNS | 70h | 3ms | 938mb |
| TailorNet | 6.6h | 11ms | 2047mb |
| SNUG | 3h | 2.2ms | 24mb |
| GarSim | 13h | 4.9ms | 163mb |
| Ours | 2.5h | 1.7ms | 96mb |
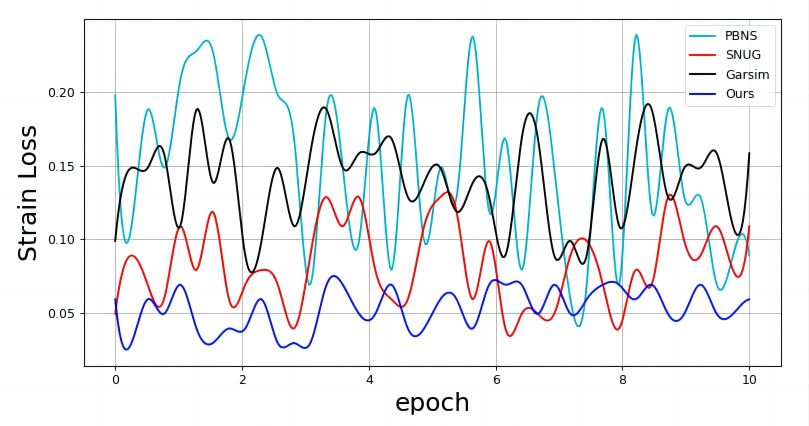
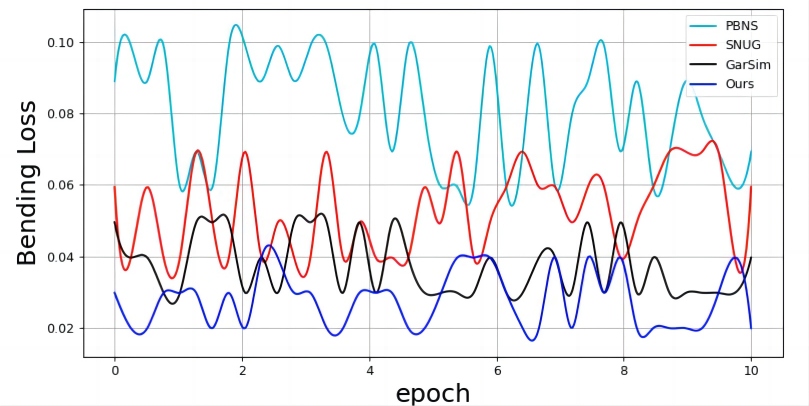
Training curve
We evaluate the errors using different physics and show that our model is better than GarSim, PBNS and SNUG in most cases.
Ablation study
We have compared the physical terms with and without our physical garment model. The table shows that our method produces deformations more in line with the physics-based simulator. As well as validating the superiority of the loss combination.
| Physical | Strain | Bend | Collision | Error |
|---|---|---|---|---|
| No phys | 0.438 | 0.121 | 3.05% | 18.23 |
| +phys | 0.062 | 0.023 | 0.69% | 16.67 |
| Loss Combination | Collision | Error |
|---|---|---|
| No Loss | 6.17% | 25.69 |
| LPhy | 5.64% | 18.17 |
| LPhy+Lf | 2.16% | 13.23 |
| LPhy+Lf+Lm | 0.66% | 11.61 |
dataset
The CLOTH3D dataset synthesizes a large amount of dressed human body data by combining garments of various styles and generating motion sequences based on physical simulation using the SMPL human body model. The resulting dataset is then rendered into corresponding images.
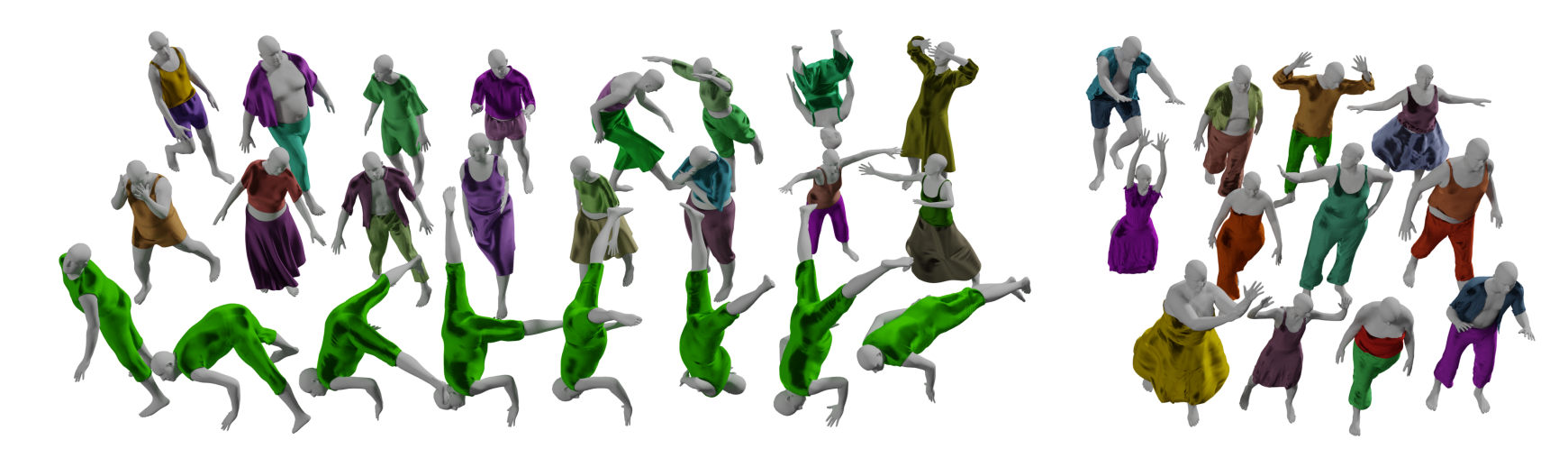

The AMASS dataset fits the SMPL model to a large amount of sparse joint motion capture (MoCap) data and estimates SMPL human body motion sequences. Although the geometric data is based on the SMPL parameterization space, their rich human motion still has important significance. A total of around nine million frames of data from approximately 300 individuals have been recovered from various MoCap datasets.
The AMASS dataset contains 40 hours of motion capture, 344 subjects, and 11,265 motions. The original datasets that comprise the AMASS dataset have 37 to 91 distributed motion capture markers. Each frame in the AMASS dataset includes SMPL 3D shape parameters (16 dimensions), DMPL soft tissue coefficients (8 dimensions), and complete SMPL pose parameters (159 dimensions), including hand joints and global translations of the body.

download

After processing with our method, the input real video can not only generate smooth video, but can also enhance the clothing in the original video and show a smoother clothing swing effect.