4月14日至4月19日,2024年度国际声学、语音与信号处理会议(International Conference on Acoustics, Speech and Signal Processing,简称ICASSP)在韩国首尔召开,我院3篇论文被录用并应邀做报告。
ICASSP由国际电子技术与信息科学工程师协会(Institute of Electrical and Electronics Engineers,简称IEEE)主办,是全世界最大、最全面的信号处理及其应用领域的顶级会议,也是CCF(中国计算机学会)推荐的B类国际学术会议,在相关领域享有较高声誉。

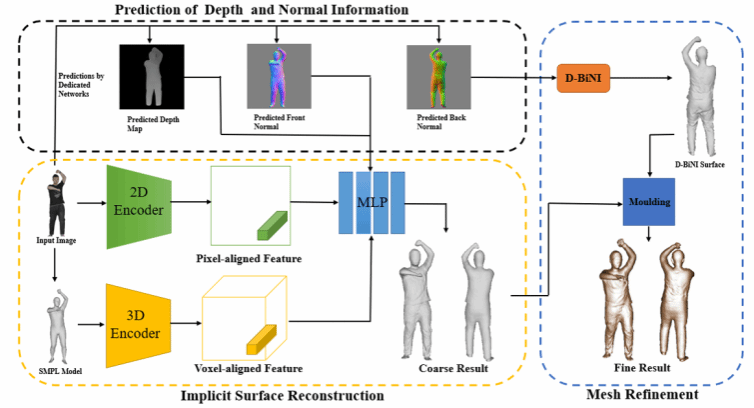
《PMDI: Combining Parametric-Model And Depth-Aware Implicit Function For Single-View Human Reconstruction》由钟赛尚和胡新荣教授共同指导完成。论文针对目前三维人体重建存在的肢体动作异常,重建精度不高,背部细节缺失等问题,提出了一种结合参数化模型和深度感知的隐式重建算法,该方法能够从单一RGB图像重建出包含服装的三维人体。首先通过优化的参数化人体模型监督全局几何特征提取,并将改进的参数化模型,前视法线图,深度先验作为参数来训练深度隐式函数。最终,我们将后视法线图转换为详细但不完整的D-BiNI表面,以修复粗糙结果,从而有效地解决了上述问题。实验结果表明,相较于传统方法,该方法有效提升了重建结果的整体质量和表面细节。
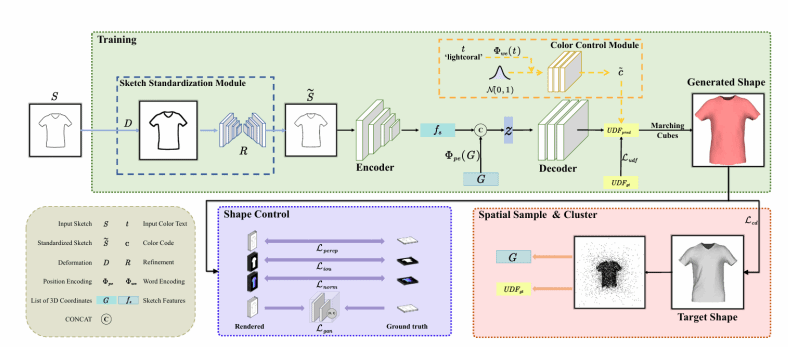
《SGM:A Dataset For 3D Garment Reconstruction From Single Hand-Drawn Sketch》由陈佳教授指导完成,论文提出了一个大规模的三维服装模型数据集——SGM(Sketch-Garment Models), 包含了从36个不同视角渲染得到的5种类别服装的渲染图,包括草图、轮廓图、剪影图、深度图和法线图。在SGM的基础上,本文构建了一个端到端的重建网络,该网络能够直接从输入草图生成能够忠实表示输入草图形状的高保真的服装三维模型。最后,本文在SGM及现有的服装三维模型数据集中进行了多样性的评估,实验结果表明,本文提出的重建方法在视觉效果和定量指标上均取得了最佳表现。
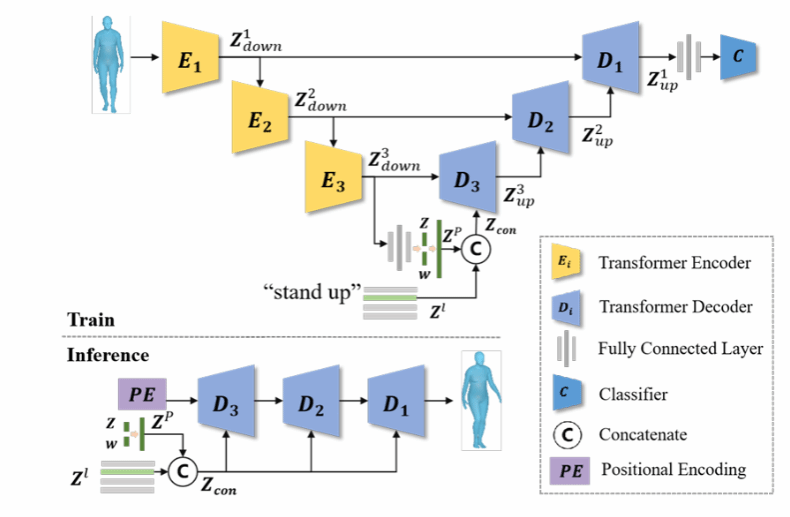
《Human Motion Generation Via Conditioned GMVAE With TUNet》由杜小勤副教授指导完成。论文提出了一种基于高斯混合模型和transformer U-Net(TUNet)的人体动作生成方法(CGMVAE-TU),该方法将隐空间建模为高斯混合分布,并推导出新的变分下界(ELBO)。为了增强模型的表现力,增强各个子高斯分布的区分度,使用费雪判别式(Fisher discriminant)作为正则化。最后,还提出了一种改进的注意力机制并应用于TUNet,仅利用动作标签就能生成与语义信息相对应的动作。在各种数据集上对所提出的 CGMVAE-TU 模型进行了评估,几乎所有指标上都超过了 SOTA,生成的人体动作逼真自然。
近年来,学院狠抓研究生培养质量,不断加大研究生科学研究的支持力度,鼓励并支持研究生走出去进行学术交流,形成了良好的科研育人学术氛围,提高了研究生的学术研究水平,提升了学院的学术影响力。